In this talk, Rsqrd AI welcomes Diego Oppenheimer, CEO and co-founder of Algorithmia! Diego goes in depth on why machine learning projects fail and why we don’t see machine learning in production despite how powerful the technology can be. He shares his experiences on the problems surrounding pushing ML into production.
Algorithmia
Algorithmia is a machine learning operations (MLOps) platform that helps data science and machine learning leaders deploy, manage, and scale their ML portfolio. It’s a fully integrated machine learning operational environment that allows someone to deploy from anywhere and securely manage a company's ML portfolio from one central location. The company has seen success in deploying AI at scale and managing the ML lifecycle.
The Problem: Machine Learning != Production Machine Learning

Diego starts off with perhaps an obvious but important point. He remarks that machine learning (ML) is not equivalent to production machine learning.
“… if you’re going to leave today with anything…it’s that machine learning and production machine learning are two completely different beasts”
There are multiple factors to consider when it comes to production ML that one may not think about when it comes to typical machine learning. We think about data collection and modeling and accuracy, but there are other important variables to consider: infrastructure, integration into DevOps tools, and deployment.
When it comes to production ML, integration into software is the “ultimate goal”. Production ML is a tool in creating an ultimate product, so thinking about how ML integrates/interacts with software is important.
Teams Can Do More
Algorithmia does a survey every year and gathers data from over 500 practitioners, and they produced some key findings:

- 75% of time is spent on infrastructure tasks, and 25% of time is spent on training models
- 30% of challenges faced are about supporting different languages and frameworks
- 30% of challenges faced are about model management tasks such as versioning and reproducibility
- 38% of challenges are about deploying models at the necessary scale
To view 2020 data, you can interact with their data visualization or read their whitepaper: 2020 state of enterprise machine learning
Teams are spending most of their time running infrastructure tasks, like setting up environments and resolving dependencies, over spending time on actual models.
There are also some key challenges that participants were facing. New frameworks and languages are being released at a considerable rate. It’s a challenge productionalizing all this technology when there seems to be new technologies everyday.
The next challenge is how to manage models. After creating a model, there are challenges in how to version the model and get reproducibility as one continuously develops their technology.
The last challenge is deploying models at an appropriate scale. Models are getting huge and they take up a lot of resources, and it’s become a real engineering challenge to deliver the software experience that someone would want while doing it at scale.
A report by Gartner also showed that the main barrier to delivering business value is lack of successful production of projects
The Problem Continued: Where to Start?
A lot of companies are only just starting to explore using ML. They have all this data and see this emerging technology, and now they’re trying to understand what to do with their data and how to use these new tools. Basically, they’re trying to figure out where to start and how to do it. How does someone make decisions with ML? What tools does someone need? Who should someone hire? When bringing in someone from a purely academic background, they are going to face challenges working in an enterprise setting.
Traditional DevOps and ML lifecycle DevOps are different. The latter requires incredibly fast iterations due to dynamic variables such as different hardware or the data changes. ML moves faster than traditional app development, and the ML development lifecycle keeps evolving. It’s a complex problem, but at the end of the day, DevOps is about making a faster path to production.

Rapid Growth of ML and Cost
When first deploying ML, it’s not very difficult. Resources are easily acquired, hosted, and managed, and the demand for the product is low. One can work with a few models and frameworks ranging between 1-2 languages, have a self-managed DevOps team, and can expect to support a few end-users.
However, things will grow exponentially. Soon, there needs to be support for hundreds of models, automated systems to help with low discoverability, and thousands of calls to an API per second. Supporting growth becomes very expensive.
A big takeaway is that the ML dev lifecycle moves really fast, and it’s important to separate ML development and application development and should be treated as such.

Tactical vs. Technical View of the Problem
Diego breaks down the problem of ML deployment into two perspectives: tactical and technical.
Tactical Perspective
Deploying ML today is economically challenging, and it’s due to a lot of factors:
| Problem | Solution | |
|---|---|---|
| Lack of Process | It’s easy to get funding and experiments running, but what needs to happen to get it into production? How do we get from POC (proof of concept) to production? |
Plan and fund deployment upfront Set clear deployment criterias Bring in stakeholders from IT and DevOps early Build for repeatability in process |
| Wrong Incentives | If you just set goals to innovate and experiment instead of deploy and align with company business, you’re not going to actually get results. What is the minimum justifiable improvement? |
Consider using MJIT (Minimal Justifiable Improvement Tree) by Ian Xiao, a framework that analyzes the cost and value of using ML |
| Wrong Teams | You can’t ask data scientists with a lack of eng. experience to build infrastructure, and teams that lack DevOps experience and are not partnering with people with the right skills can’t succeed Does my team have the right skill set to make my solution deployable in the organization? |
Create hybrid teams of engineering, data scientists, and DevOps engineers Don’t chase people who can do everything: hard to find Invest in software and platforms that enhance data science and ML teams |
| Lack of Proper Champions | ML projects without executive sponsorship rarely make it to production, and risk and fear of failure get in the way of have proper supporters (champions) How to get buy-in from stakeholders? |
Align values and interests Involve stakeholders up and down the command chain early Collaborate to achieve goals vs dictating all the decisions |
| Wrong Technology | Lack of best practices, not building for measurability and repeatability, not thinking about access to data, and not addressing the differences between product and development will hurt prospects of deployment What is the best ML architecture for my organization? |
Design to execute at scale, repeatedly and efficiently Replace and upgrade components as needs evolve Anticipate and allow a variety of tools and technologies to be used concurrently at every step of the cycle Remain open to integration with the variety of in-house technologies |
Technical Perspective
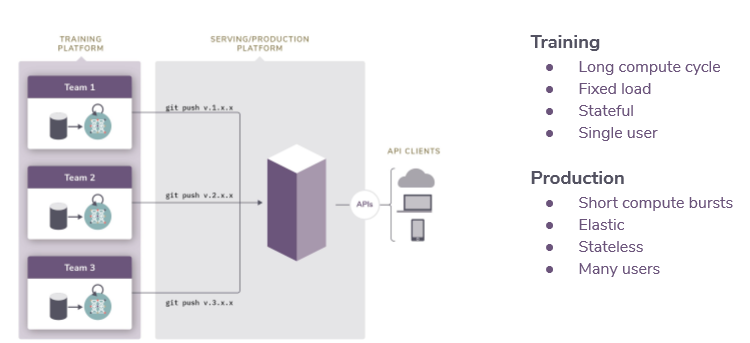
The following is a simplification of the ML lifecycle and how Algorithmia views the process: data > train > deploy> manage

Connect to your data management system, publish from your training platform of choice via API, Git, or CI/CD pipeline, deploy and manage models, and integrate with your other models and consuming product applications.
Things to Consider
Training and Production are Different
Training and production conditions are very different. Training has long compute cycles, fixed loads, is stateful, and has a single user. In production, one has short compute bursts, needs elasticity, can be stateless, and has many users.
Heterogeneous Tooling and Dependencies
There are dozens of combinations of different frameworks, languages, hardware, and dependencies. As mentioned before, it seems like new tech emerges every day. The first time someone builds a stack, one thing is making it all work. As they build, they need to fit everything in a way where each one of these dependencies can be upgradable.
Composability Compounds the Challenge
A lot of models don’t make it into production because they fall apart before making into production, and one wants to be able to patch these pieces. How dependencies and pieces fit together are really important. ML models are built out of pipelines, and someone would want every piece of that pipeline to be the best piece it can be. Dependencies can get very complex and they want to be able to break them down into pieces.

Diversity Complicates Auditability and Governance
One needs to make sure they’re compliant with their organization’s rules. Some big questions are who’s calling what, who can access it, and how does someone govern dependencies? Diego recalls a story from a financial services customer where they had a lot of security measures surrounding dependencies, packages, etc. Data scientists kept pulling things from PyPy with no checks, and the DevOps team became livid when they found out.
Lack of Reusability Slows Growth
Everyone should build for reusability. Constantly reinventing the wheel and rewriting the same function becomes inefficient and wastes time on updating dependencies. It’s a better practice to build reusable services that can be used throughout the organization.
Measuring Model Performance
Success and performance are very context-dependent. In academia, the goal is to find truth and to improve accuracy. If it takes 10 years to increase accuracy to 93% from 90%, that’s a valid investment. In enterprise, it’s not the same. For example, if someone buys something on Amazon and gets recommended the same item, it’s not a big deal. The success of these two situations depends on the context, goals, and priorities. No one solution is right for each job.

How to Navigate Common Pitfalls and Key Takeaways

Diego quotes a friend with the following remarks about navigating through all the aforementioned considerations:
- Don’t reinvent the wheel
- Outcomes, not process
- Don’t try to be perfect
- Say no to lock-in
- Tools aren’t solutions
- Audit honestly, revise constantly
Conclusion
If there’s anything to take away from this talk, it’s
“Machine Learning != Production Machine Learning!!”
Cool Stuff to Check Out
Video: Rsqrd AI - Diego Oppenheimer - From R&D to ROI of AI
Data Science is boring by Ian Xiao
The Roadmap to Machine Learning Maturity
Hidden Technical Debt in Machine Learning System
Interesting questions
- What are your challenges in productionalizing deep learning? 32m 07s
- When selling to enterprises and you have an executive sponsor, a lot of the core issues are setting the right expectations to what outcomes you want to achieve. What are your experiences working across different industries on how to deal with those questions of setting the right expectations with your sponsors to help them feel very confident about some reasonable way of recouping their ROI on investments. 38m 40s
All ideas and information presented in this post are that of the original speaker unless otherwise noted